
To study waves, one must calculate. To calculate requires creating software. If it’s not simple, a build system and souce control system help keep things straight.
Every few years I look over the landscape of build systems to see what’s new, what’s different, and if I might like to choose a different favorite for my own general use and to recommend for projects at work.
Peeking ahead, The Conclusion: CMake is the winner in most cases, with QMake a close second if there’s only one target.
Sometime around ten years ago I chose Peter Miller’s Cook for personal projects because it seemed elegant, useful, and solved some problems of using plain Makefiles. For a large project containing several executables, several libraries, user documentation and technical documentation, it is common to have a Makefile, or whatever files a build system uses, for each of those components, and a master file to invoke them. This is done all the time with Makefiles. But there are problems with that – conveying values of variables, having to repeat dependencies, lists of linker options, and so forth, and worst of all, having to re-determine file obsolescence over and over as each Makefile determines the work needed for its target. Cook solved some of those problems, as did several other newer build systems. What is desired, ultimately, is to spend little time on build system activities compared to actually compiling and linking. In particular, a null build (when all target files are up to date) should run “quick” which for most us, should be just a few seconds if not in an apparent instant.
The key paper on this, “Recursive Make Considered Harmful” by Peter Miller, is required reading for all computer scientists, software engineers, and science-math-art types like me who pretend to be such. It can be found in numerous places on the WWW.
Another important characteristic of a good build system is platform independence. Make and Cook both fail at this, due to using shell commands for carrying out build steps. It is impossible to write a command to compile on Linux or BSD, and have it also work on Mac, and also on Windows, and also on all the popular embedded systems. This is not just a matter of hiding “gcc” or “clang” or “CL” behind a macro $(CC) along with their more common options. Abstraction to the point of telling the build system to “compile” a .cpp file to get an object file (and we don’t have to say if it’s “.o” or “.obj”) allows platform-independent builds.
Along with this, is the fact that most Windows developers like to use MS Visual Studio. Most linux/unix developer are happy with a command line, though a variety of IDEs could be in use. Java and Android developers tend to use Eclipse. Abstraction of specific commands into named concepts allows the build system to produces artifacts that aren’t command-based, such as IDE project files, and files for less abstract build systems such as Makefiles.
This sort of build system, highly abstract and which produces files for simpler build systems, could be called a Second-Order Build System. These seem to be the winning technique throughout industry. CMake excels at this.
CATEGORIES of BUILD SYSTEMS
* Simple direct build systems
: Make, Cook, Rake. Often limited to few platforms, specific toolchains. Easy to learn, use, test. Horrible once you want to scale up or spread to other tools, platforms.
Main benefit is these are easy to learn, having a simple basic working principle.
Easy to set up for tiny projects, as long as you don’t want portability.
Fine for in-house one-off projects.
* Powerful Self-Contained Build Systems
, providing abstraction and portability, which do all the work themselves such as finding platform-dependent libraries, fiddling with paths, invoking compilers. Scons is an example.
* Second-Order Build System
, also abstract and portable, but don’t do the work themselves. Instead these systems degate the blue-collar work to simpler build systems, which is nearly always Make. A second-order build system creates Makefiles or IDE project files. Beware the dangers of Recursive Make. Widely used examples: QMake, CMake.
* Specialized Build Systems
– just for a certain language, maybe only on a specific platform. Unlike the Simple Direct Build Systems, these don’t even pretend to be portable or abstract. Fine for academic exploration, specialized embedded systems, cutting edge new hardware. Use one of these if necessary, but otherwise avoid. Not discussed further in this article.
* No Build System
. Some languages such as the “scripting” ones, like Python, Perl do not need compiling. A byte-code compiled file may be created by the interpreter, but is handled entirely by the interpreter. It is hardly a build system. In other cases, no build system is fine for students writing “hello world”, researchers trying out experimental compilers, and offbeat platforms lacking a normal set of tools.
REQUIREMENTS and DESIRED CHARACTERISTICS of a GOOD BUILD SYSTEM
Popularity
* Well established, well-used. We can rely on it for mission-critical work, company jewels. Must have escaped its crib of origination, gotten into the hands of many users with no connection with the inventors. Exception: for those who love intellectual adventures, debugging, and have ample spare time for writing and submitting patches, then never mind. This exception is not applicable to me or anyone I know.
* Good documentation, good online support, widespread know-how. We do not want to be often scrutinizing the build tools’ source to figure out how to use it.
* One way to see if a tool has popularity, support, and community is to run a half-hearted superficial Google search. (Or a duck-duck-go search.) When not trying hard, success stories, blogs, tutorials and more should come up anyway. This is evidence that the tool has escaped its crib.
Logic and Efficiency
* Can build just one component of a large system. If the source control allows it, a developer should be able to pull just one major component with its dependencies, compile it, debug it, and submit changes. Some build systems insist on running only from the top level.
* Quick null build (all files already up to date)
* Multiple out-of-tree builds (diff CPU, demo/real, debug/release, ..)
* Faster is better than Slower. (Duh!)
* Not cumbersome for tiny projects.
Targets and Development Environments
* Can build on and target Windows, Linux, with future targets that may include OSX, iOS, Android, various embedded systems.
* When building on Windows, can create files for Visual Studio.
* On Mac, files for XCode.
* There is no IDE of choice on Linux, but perhaps support for Eclipse would be nice – if only as an indication that the tool can support a wide variety of development environments.
Toolset flexibility
* Choice of compiler: gcc vs clang. Could we use clang for Windows projects? Sure, anything is possible these days, but how easy will it be to support stunts like that in the build system?
* No hand-writ dependencies (like xxx.c : xxx.h common.h seen in Makefiles) (but can be done if necessary)
* Easy to incorporate external library, component, etc w/o much fuss.
* While C, C++ will be our main languages, should not be confined to working with those.
Installation and Ramping Up
* Using the build tool does not require installing forty other things, esp not obscure languages, libraries which in turn drag in tons of stuff
* Easy for an experienced developer, not expert on the build system, to figure out how to use it for a typical medium-sized project.
WORTHY CANDIDATES
With comments, evaluations, links. Highly biased, based on my limited knowledge and search time.
GNU Make
Simple direct build system based on famous old unix ‘make’.
Very unix/linux oriented. Uses shell commands.
Original make on unix created 1970s, grew popular long ago, now universal.
http://www.gnu.org/software/make/ – current
GNU license.
GNU Autotools = Autoconf, Automake
Tools to generate Makefiles, adapting them to specific machines according to 32/64 bit, availability of libraries, optimization levels.
Widely used for GNU and other open source projects.
Messy system that grew over time into rat’s nest of detail.
Difficult to learn. Very unix/linux oriented, shell commands.
Only build system for which the word ‘arcane’ is used.
http://www.gnu.org/software/automake/ – current
https://autotools.io/index.html (2013)
GNU license.
CMake
Second-Order Build System, covering all significant platforms, architectures.
From ITK, maker of VTK 3D data visualization software.
Though it creates recursive makefiles on linux, the problems with that are anulled
because cmake stays in charge during dependency checks, writes clever makefiles.
Used by many large projects, open source and proprietary.
I am familiar with CMake for NRAO’s CASA radio astronomy software. It worked well.
CMake is used by ROOT, the major software tool used for high energy physics at CERN.
Used by: OpenCV, Point Cloud Library, zlib, Armadillo, OGRE 3d engine
Can build an individual target, but by name at top level,
not by cd’ing down and building there.
Created ~2000, grew within science and 3D graphics community,
then mid-2000s started catching on more widely.
http://www.cmake.org/ – current
http://aosabook.org/en/cmake.html
QMake
Second-Order Build System.
Primarily for Qt-based C++ projects, requiring special preprocessing.
Can be used for non-Qt projects, but this is rarely done.
Easy to learn, get going on small projects.
Simple clean language. Add source file with elegant lines like
HEADERS += foo.h
SOURCES += foo.cpp
Deal with common conditional situations with code like
!exists( main.cpp ) {
error( "No main.cpp file found" )
}
win32 {
SOURCES += win32demoscreen.cpp
}
Easy to deal with platform variations, since Qt already aims to be cross-platform.
But its biggest flaw: makes only one target per *.pro file. It is possible
to have many .pro files, and have QMake create as many Makefiles, with a master
Makefile to rule over them, but it is not clear to me if this is a good idea. Also,
one may define multiple “configurations” in one .pro, each providing one target, but
you must manually run qmake once for each config.
http://doc.qt.io/qt-5/qmake-overview.html
https://blog.qt.io/blog/2009/10/12/to-make-or-not-to-make-qmake-and-beyond/
Boost.Build
Created for Boost libraries.
Handles all platforms of interest, variety of toolchains. Since the Boost libraries
strive hard for universal portability, it makes sense their build tools would follow.
http://www.boost.org/build/index.html
Boost License
Scons
Python-based direct build system.
Was used by NRAO for CASA, until they switched to CMake.
(Parts are still scons, or have scons and cmake as redundant build systems.)
Good at handling many files spread over complex directory tree, with
the resulting file much smaller than equivalent Makefiles, perhaps 1/4 to 1/10th size.
Weak at IDE support – does not create .proj etc but instead, you must teach
your IDE (VS, XCode or whichever) to run scons as an external command or script.
see https://bitbucket.org/scons/scons/wiki/IDEIntegration
Even so, just isn’t nice with Windows development.
Anyone who tries feels it’s a strain, and is happy to move to something else such as cmake.
Can build out of source tree, but there’s a bit of a trick to it (2010)
http://stackoverflow.com/a/1763804/10468
“ridiculously long incremental build times just checking if anything had changed.” (2009, not finding anything recent to counter this claim.)
Uses Py 2.7, nothing earlier.
Created around 2000. Projects and praise from users: http://www.scons.org/refer.php
As of 2014-2015, slowly moving toward Python3. Current version of scons is 2.3.5
http://www.scons.org/
https://bitbucket.org/scons/scons/wiki/SconsVsOtherBuildTools
WAF
Runs fast, so they say.
Re-design of scons to improve its worst features
“it is essentially a library of components that are suitable for use in a build system”
(ugh, if that’s like how Drupal isn’t a CMS but components to build your own CMS, I’m outta here!)
Waf is used in a number of non-trivial projects, none of which I have any personal familiarity.
http://code.google.com/p/waf/ https://en.wikipedia.org/wiki/Waf
https://waf.io/book/ (2015)
Apache Ant
and related tools Maven et al
Used in large, or any size, Java projects.
Heavily uses XML. I do not fancy hand-editing XML.
http://ant.apache.org/
Ninja – NEW (to me)
Created to deal with Chromium’s thirty thousand source files. Minimalist, fast,
and intended to be the lower-level output of some higher-level, more abstract build generator.
Higher-level generators include gyp, CMake.
Might be worth looking into, trying on a small toy project, but for
now, there’s not enough anecdotal evidence, big users to form any opinions.
Created in 2011. Last revision 2015.
http://neugierig.org/software/chromium/notes/2011/02/ninja.html
http://martine.github.io/ninja/manual.html
tup (NEW!)
Fast, “correct” (not clear exactly what that commenter had in mind saying this)
Not enough usage yet out there to establish solid opinions
Did not pass my “half-hearted superficial Google search” test.
http://stackoverflow.com/a/24953691/10468 compared to cmake, autotools
http://gittup.org/tup/
http://gittup.org/tup/make_vs_tup.html
IGNORED
A-A-P
Alternative build system.
Read about it around ten years ago. Does not just build, but also delivers the result, being more intelligent about installing than “make install”.
Never heard of anyone actually using this, even to try it out when looking at other build systems.
http://www.a-a-p.org/
Rake
Ruby is an elegant language. Rake uses Rakefiles, like Makefiles but
written in ruby, with powerful data structures, blocks (lambdas) and so forth.
I’ve found setting up a Rakefile to do anything tedious, taking more
know-how than I care to spend, especially after using CMake, QMake and others
Cook
Just hasn’t caught on, despite widespread fame of its creator’s paper.
Still has the problem of Make, with build operations given as shell commands.
WHO SWITCHES AND WHY?
* NRAO CASA switched from scons to cmake. with custom scripts, cmake was easier to administer and do everyday tasks such as add new source files. Null builds were slow, and there were some problems with dependency analysis between the dozens of target libraries and executables.
* (2005) An open source game engine went from cmake to scons. Very strong Python culture. Today, they appear to be developing on only Visual Studio, supporting Windows only.
* Open Office (not sure if before or after the split to Libre Office) had been using
perl scripts, then decided to use CMake. The switch was a long slow process,
* Many stories can be found on “success stories” pages and “projects using ___” pages, and Q&A forums of all sorts. Most common reasons are: dealing with too many files, needing oddball tools supported, and reducing build time.
FAVORITES
QMake – for the elegant langauge, power, portable, right level of abstraction
CMake – almost as elegant, but a bit more powerful than QMake due to ease of
handling multiple targets.
For my personal projects, if there’s a GUI it’ll be Qt, so I’ll use QMake.
For projects involving a team, multiple target components, with or without GUI,
you can’t go wrong choosing CMake.
I might try boost.build out of curiosity, but not for anything multi-platform, since
it can’t make VS .proj files, or the equivalent for XCode. Otherwise, on a slow weekend I might toy with Rake, since I like the elegance of Ruby, or WAF since I don’t know enough about it.
HOW DO BUILD SYSTEMS DECAY?
1. Great new system is invented.
2. Doesn’t deal with general patterns like *.c –> *.o so wildcards are added
3. Want Release and Debug, or Demo, Standard and Pro versions…
4. Want out-of-tree builds, or access to source via different than default paths
5. Need to handle versions of OS, libraries, toolsets; can’t just hide behind some macro
6. More complex project has several target executables, needs more sophisticated logic
to execute the same build logic but with some variations.
7. Tool becomes badly-designed full-blown language interpreter!
MY BIASES and PREJUDICES
Don’t make any major company-wide decisions bases on what I say!
* I have used CMake, QMake, Scons, hand written Makefiles, and have tried without any great depth Rake, Cook, IMake, waf, and some others.
* Like all Linux users, I have done the “configure; make; make install” dance a thousand times. I have not tried to set up autotools for a project, and gotten anywhere. My last attempt to work through a tutorial and go beyond it was in 2002, when I was at Colorado State.
* Most of my software work has been on small-scale projects or well-defined small parts of larger projects. Occasionally I work on a larger project, in which case the build system has always been scons or cmake.
* Most of my work has been for in-house use by scientists, engineers, specialists. Some has been open source and some has been proprietary. Almost entirely the subject matter is graphics, imaging, computer vision, scientific computing, signal processing, laboratory data acquisition and such. I don’t touch business software, web apps, or consumer shrink-wrap even if I have a ten foot pole handy.
MISC EXTRA READINGS
(links not already mentioned)
Comparisons of builds systems, rationales for switching
* https://wiki.openoffice.org/wiki/Build_System_Analysis (cmake, perl)
* http://stackoverflow.com/a/18291580/10468
* https://wiki.openoffice.org/wiki/Build_System_Analysis#Analysis_of_the_current_build_system compares cmake, gnu make in depth
QUOTE from designer of QMAKE
https://blog.qt.io/blog/2009/10/12/to-make-or-not-to-make-qmake-and-beyond/ about creation of qmake
CMake, for example, relies on the Makefile generator, and creates Makefiles which in turn calls back into CMake to do the build. This solution is not only fork-heavy, but also limiting, since you can only parallelize as well as the backend generator allows you to. So, unless the output Makefile is one single huge Makefile, you’ll run into limitations.
Scons will build directly, but is too slow at parsing dependencies, so each build you do takes forever to start. Waf is better in this respect, but both lack a proper set of backends for project generations (Vcproj, XCode, Makefiles etc). They are also based on Python, which adds a dependency of a 3rd party library, which we want to avoid due to both the multitude of platforms Qt supports, and because of all the utility libraries.
On the Hairy Growth of new Tools into Monsters
Quote from SomeCallMeTim on ycombinator, 2013
When people (myself included) start taking advantage of the fact that Make is Turing-complete and writing arbitrary “programs” in their Makefiles, it typically starts simple; you want to do something like build ALL the files in a folder, so you use a wildcard. Then you want to add dependency checking, so you use the wildcard to convert between .o to .d, keeping the same folder structure. And I don’t want the .o and .d files to be generated where the .c files live, so I need to add this code here that converts the paths.
OOPS, this project uses a slightly different folder structure, and so I need to add a case where it looks in DIFFERENT relative paths.
Oh dear; I just realized that I need this code to work ALMOST the same in a different project that needs to be built with the same Makefile; that means I need to include it twice, using different options each time.
And it turns out that it DOESN’T work the way I expect, so now I have to use $(eval), meaning some of my Make variables are referenced with $(VAR), and some with $$(VAR), depending on whether I want them to grab the CURRENT version of the variable or the calculated version.
But now, now I have all of my code to create my project in one convenient place, and creating a new project Makefile is quite trivial! It’s all very clean and nice.
But the next person to try to change the folder structure, or to otherwise try to get this now-crazy-complicated house of cards to do something that I didn’t anticipate has to become just as adept at the subtleties of $(eval …) and Makefile functions (define …); error messages when you get things wrong tend to make early C and C++ compiler errors look straightforward and useful by comparison.
For a far more complicated example, take a look at the Android NDK Makefile build system. 5430 lines of .mk files that make your life very easy…right up until you want to do something they didn’t anticipate, or until they ship a version with a bug (which they’ve done a several times now) that screws up your build.
>>>








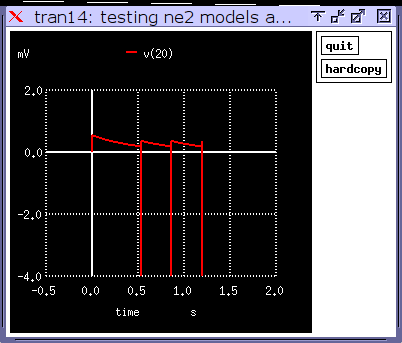



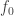 . Period is seconds (or milliseconds) per cycle, while frequency is cycles per second.
. Period is seconds (or milliseconds) per cycle, while frequency is cycles per second.


 , being the first of those, would be called the “first harmonic”, and
, being the first of those, would be called the “first harmonic”, and 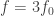 the “second” and so on. Indeed, some logic-minded authors write that way. But it’s confusing. The far more common convention is to include the Fundamental as one of the harmonics. The captain of a ship is still a member of the crew, right? That allows the numbers to match:
the “second” and so on. Indeed, some logic-minded authors write that way. But it’s confusing. The far more common convention is to include the Fundamental as one of the harmonics. The captain of a ship is still a member of the crew, right? That allows the numbers to match:  is the “twenty-ninth harmonic” and so on. Much nicer!
is the “twenty-ninth harmonic” and so on. Much nicer!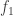 ? It is not the zeroth harmonic, is it? But oh well.. Humans and their primitive math and illogical language…
? It is not the zeroth harmonic, is it? But oh well.. Humans and their primitive math and illogical language…

 , zeros out, along with any even harmonic.
, zeros out, along with any even harmonic.






